
.png)
1. What is Data Anonymization:
Data anonymization is the process of transforming personal data in such a way that individuals cannot be identified directly or indirectly. This process involves altering or removing personally identifiable information (PII) to ensure that the data cannot be traced back to a specific individual, thereby protecting their privacy.
2. Importance of Data Anonymization
The importance of data anonymization lies in its ability to protect individual privacy while still allowing for the utility of data. In an age where data breaches and privacy concerns are prevalent, anonymization is crucial for organizations to maintain trust, comply with data protection regulations, and mitigate the risk of identity theft.
3. How Data Anonymization Works
Data anonymization works by modifying identifiable information in datasets so that individuals cannot be recognized. This can be achieved through various techniques such as data masking, data swapping, and generalization. By rendering the data anonymous, organizations can safely share or analyze it without compromising personal privacy.

4. The Role of Anonymized Data in Data Privacy
Anonymized data plays a pivotal role in data privacy by enabling organizations to use and share data for analysis, research, and other purposes without exposing sensitive personal information. This balance between data utility and privacy protection is essential in sectors like healthcare, finance, and marketing, where data-driven insights are crucial.
5. Types of Data Anonymization
a. Partial Anonymization
Partial anonymization involves altering only certain parts of the data that are directly identifiable. This method reduces the risk of re-identification while retaining some level of data specificity, making it useful for scenarios where complete anonymization is not feasible.

b. Full Anonymization
Full anonymization ensures that no individual can be identified, directly or indirectly, from the data. This technique is more stringent and often involves removing or encrypting all identifiable information. Full anonymization is essential for sharing data in highly sensitive contexts.

c. Pseudonymization
Pseudonymization replaces identifiable information with pseudonyms or codes. While this method maintains a level of data utility and allows for re-identification under certain conditions (such as by authorized personnel), it is less secure than full anonymization but often more practical for ongoing data use.

6. Techniques of Data Anonymization
a. Data Masking
Data masking involves hiding original data with modified content. Techniques include shuffling data within the same dataset or replacing sensitive data with random characters. Data masking is particularly useful for protecting data in non-production environments like testing or training.
Data Masking can be done through,
i. Substitution:
Replace real data with fictitious but realistic data. For example, replacing real names with randomly selected names from a predefined list.
ii. Shuffling:
Rearrange data within the same dataset to anonymize the records. For instance, swapping phone numbers among users while keeping the original structure intact.
iii. Encryption:
Convert sensitive data into a coded format that can only be read with a decryption key. For example, encrypting social security numbers before sharing datasets.
b. Data Swapping
Data swapping, or shuffling, rearranges data within a dataset. For example, the addresses of individuals in a dataset might be swapped randomly. This technique maintains the overall structure and statistical properties of the data while protecting individual identities.
Data Swapping can be done through,
i. Attribute Shuffling:
Shuffle the values within a single attribute. For example, shuffling birth dates within a dataset to anonymize the records.
ii. Record Swapping:
Swap entire records between different entries. For example, swapping all details of two users except their IDs to protect their identities.
iii. Proportional Shuffling:
Maintain the distribution of values while shuffling. For instance, ensuring that swapped ages still reflect the original age distribution of the dataset.
c. Generalization
Generalization reduces the precision of data to prevent identification. For instance, exact ages can be replaced with age ranges. This technique helps in maintaining the utility of the data for analysis while safeguarding privacy.
Generalization can be done through,
i. Range Generalization:
Replace specific values with a range. For example, replacing exact ages like 23, 24, and 25 with an age range of 20-30.
ii. Hierarchical Generalization:
Replace detailed data with broader categories. For example, replacing a detailed address (123 Maple St.) with a broader region (Central District).
iii. Aggregation:
Combine data points into a summary form. For example, instead of showing individual salaries, display the average salary for a department.
d. Suppression
Suppression involves deleting or omitting parts of the data. This can be done to remove the most sensitive elements entirely. While this method is highly effective in preventing identification, it can also significantly reduce the usability of the data.
Suppression can be done through,
i. Partial Suppression:
Suppress only certain parts of the data. For example, masking the last four digits of a social security number (e.g., 123-45-XXXX).
ii. Full Suppression:
Remove entire data elements. For example, removing the address field entirely from a dataset.
iii. Conditional Suppression:
Suppress data based on certain conditions. For example, removing the salary field for all employees earning above a certain threshold.
e. Differential Privacy
Differential privacy adds noise to the data, making it difficult to identify individual entries while preserving the dataset's overall utility. This advanced technique is particularly useful in statistical analyses and machine learning models, as it allows for accurate insights without compromising privacy.
Differential privacy can be achieved through,
i. Laplace Mechanism:
Add noise drawn from a Laplace distribution to numerical data. For example, adding small random values to each salary in a datasets.
ii. Exponential Mechanism:
Choose data outputs based on a probability distribution that favors less sensitive information. For example, selecting which query results to show based on their privacy impact.
iii. Randomized Response:
Allow respondents to answer sensitive questions with a degree of randomness to protect their privacy. For example, flipping a coin to decide whether to tell the truth or provide a predefined response in surveys.

7. Benefits of Data Anonymization:
a. Protect Data Privacy
Anonymization enhances data privacy by ensuring that individuals cannot be identified within datasets. This protection is vital in maintaining public trust and complying with data protection laws.
b. Regulatory Compliance
Data anonymization helps organizations comply with stringent data protection regulations such as PDPA, GDPR, and CCPA. By anonymizing data, companies can avoid heavy fines and legal repercussions associated with data breaches and privacy violations.
c. Data Utility in Analytics and Research
Anonymized data retains most of its value for analytics and research. Organizations can analyze trends, conduct studies, and generate insights without compromising personal privacy, thus driving innovation and informed decision-making.
d. Risk Reduction
Anonymization significantly reduces the risk of data breaches and identity theft. Even if anonymized data is exposed, the lack of identifiable information protects individuals from harm, thereby minimizing potential damage to the organization.
8. Disadvantages of Data Anonymization
a. Loss of Data Accuracy
One of the primary disadvantages of data anonymization is the potential loss of accuracy. Altering data to protect privacy can lead to less precise datasets, which may affect the quality of insights and decisions derived from the data.
b. Loss of Data Utility
Data anonymization has an inverse relation with data utility. When anonymizing data organizations have to trade off data utility by suppressing, masking, or destroying data that is often required for extensive machine learning making anonymized data partially useless for data engineers.
c. Complexity in Implementation
Implementing data anonymization techniques can be complex and resource-intensive. Organizations need to balance privacy protection with data utility, requiring sophisticated tools and expertise.

9. Data Anonymization has Re-identification risks:
Data anonymization, a technique designed to obscure personal information, is frequently insufficient for safeguarding privacy. Research indicates that 87% of the population can be reidentified by cross-referencing seemingly non-identifiable attributes such as gender, ZIP code, and date of birth. Although reidentifying anonymized data involves intricate processes, it remains achievable, thus undermining data privacy. This vulnerability not only limits the utility of anonymized datasets for data scientists but also compromises the security of the data.
How Re-identification Works:
i. Linking External Data Sources:
Reidentification typically begins by linking anonymized datasets with external data sources. Publicly available databases, voter registration lists, or social media profiles can provide the additional information needed to match anonymized data to specific individuals. For example, a person’s ZIP code, gender, and date of birth might be cross-referenced with public records to pinpoint their identity.
ii. Triangulation Method:
By triangulating data points, such as combining multiple quasi-identifiers (attributes that can potentially identify individuals when used together), attackers can narrow down the possibilities. In many cases, the unique combination of gender, ZIP code, and date of birth is sufficient to single out an individual within a population.
iii. Algorithmic Matching:
Advanced algorithms and machine learning techniques enhance the accuracy and efficiency of reidentification. These algorithms analyze patterns and correlations within large datasets to identify matches. For instance, clustering algorithms can group data points based on similarity, helping to reidentify individuals by comparing anonymized records with known datasets.
iv. Use of Auxiliary Information:
Auxiliary information refers to additional knowledge that an attacker might possess about a person, which can be used in conjunction with the anonymized data. This could include partial information such as age range, occupation, or a known list of acquaintances. Attackers leverage this auxiliary information to increase the probability of accurate reidentification.
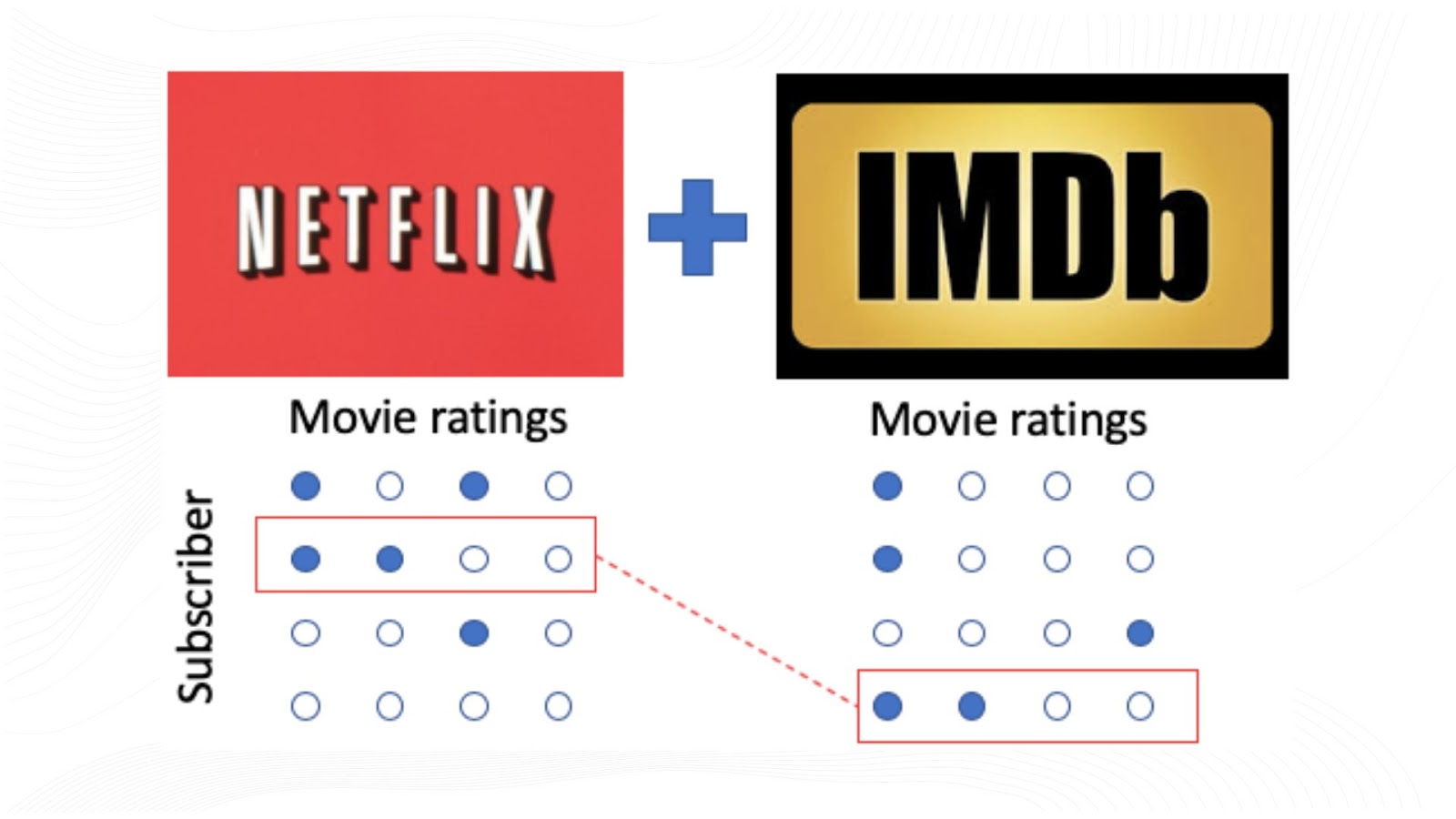
v. Privacy Attacks:
Various privacy attacks, such as the famous Netflix Prize case, demonstrate how seemingly anonymized data can be de-anonymized. In this case, researchers were able to identify individual users by correlating anonymized movie ratings with reviews on the Internet Movie Database (IMDb), showcasing the risks inherent in anonymized datasets.

10. Difference Between Legacy Data Anonymization and Synthetic Data
a. Legacy Data Anonymization
Legacy data anonymization refers to traditional methods used to anonymize data, including techniques such as data masking, generalization, and suppression. These methods involve modifying existing datasets to obscure personal information while attempting to maintain the utility of the data for analysis.
b. Synthetic Data
Synthetic data, in contrast, is artificially generated data that replicate the statistical properties of real data without containing any actual personal information. It is produced using advanced algorithms and simulations to create datasets that are both safe to use and share, ensuring privacy and utility.
c. Key Differences
The key differences between legacy data anonymization and synthetic data lie in their approach and effectiveness. Legacy anonymization alters real data to protect privacy, while synthetic data generates entirely new datasets. Synthetic data often offers higher utility and zero risk of re-identification compared to legacy methods.

11. Why is Synthetic Data Better than Legacy Data Anonymization?
a. Increased Data Utility
Synthetic data excels in maintaining data utility by accurately preserving the statistical properties and relationships inherent within the dataset. This fidelity allows for robust analysis and insightful data-driven decisions without risking exposure to personal information. Unlike traditional anonymization methods that often degrade data quality through generalization or suppression, synthetic data retains the structure and correlations necessary for meaningful analysis.
b. No Risk of Re-identification
Synthetic data inherently eliminates the risk of re-identification since it does not contain any real personal information. Each data point is artificially generated, ensuring that it cannot be traced back to an individual. This makes synthetic data a significantly safer option for data sharing and analysis compared to legacy anonymization techniques, which remain susceptible to sophisticated re-identification attacks.
c. Enhanced Flexibility and Scalability
The generation of synthetic data offers unparalleled flexibility and scalability. It can be produced on-demand and customized to meet specific requirements, whether for testing, training, or research purposes. This adaptability makes synthetic data an ideal solution for various applications, allowing organizations to create large, diverse datasets without the constraints associated with collecting and anonymizing real data.
d. Remove Bias in Data
Synthetic data can be engineered to reduce or eliminate inherent biases present in original datasets. By carefully crafting the data generation process, it is possible to ensure a more balanced representation of different groups and scenarios. This leads to fairer and more equitable models and analyses, helping to mitigate issues of discrimination and bias that often plague real-world data.
e. Immune to Data Privacy Laws
Since synthetic data does not include personally identifiable information (PII) from any real individuals, it is generally exempt from data privacy regulations such as PDPA, GDPR and CCPA. This exemption accelerates data access and sharing, as organizations can bypass lengthy compliance processes while still ensuring privacy. The immunity from these laws also facilitates faster and broader data collaboration, driving innovation and efficiency.

12. Conclusion:
Data anonymization remains a crucial practice for protecting individual privacy while maintaining data utility. However, traditional anonymization techniques are increasingly vulnerable to re-identification and often compromise data quality. Synthetic data presents a superior alternative, offering higher utility, reduced risk, enhanced flexibility, bias mitigation, and immunity from stringent data privacy regulations. As such, synthetic data should be a key consideration in modern data privacy strategies, enabling secure and effective data utilization.
