


1. What is Synthetic Data:
Synthetic data is artificial data that mimics the statistical properties of real data. It is generated through machine learning models trained on real data and then processed to replicate that data creating 100% secure programmatic synthetic data. Synthetic data by nature does not contain any personally identifiable information (PII) making it the preferred choice for enterprises for training fair and non-baised AI/ML models.
Read our extensive guide on synthetic data here.

2. Types of Synthetic Data:
a. Structured Synthetic Data:
Structured synthetic data is represented in a tabular format following a predefined schema where data (rows) and features (columns) have a defined relationship with each other and can be easily queried. Financial data is probably the best example to give when talking about structured synthetic data because it is made up of hundreds of data points organized in a rational database.

b. Unstructured Synthetic Data:
Unstructured synthetic data is data represented in media formats such as audio, images, or video formats. This data usually does not have a predefined schema or structure. Unstructured synthetic data is used for training models for autonomous driving, facial recognition, speech recognition, building simulations, and so on.

While unstructured synthetic data is an art and science in itself, In this blog we will focus on generating tabular synthetic data using GANs and LLMs.
Read about types and classes of synthetic data here.
3. Tabular Synthetic Data for Machine Learning:
Tabular synthetic data was created out of the necessity of keeping up with the data needed for ML training. Organisations thrive on data but data is limited under data privacy and protection laws making it impossible for organisations to harness the full potential of production data.
Legacy anonymization techniques such as encryption, k-anonymity, data masking, etc, were proving inadequate for fast-moving and exponential growth organizations since their need to collect, store, share, and utilize data far outweighed the pace at which anonymized data can be used and protected. This created a major gap between what was expected of an ML model versus what was obtained.
a. Challenges Using Anonymized Data:
i. Loss in Data Utility:
Data utility and data anonymization have an inverse relationship with each other. Organizations have to choose between a trade-off between either low encryption, masking, or destruction of data risking data breaches, or low data utility risking poor functioning ML and AI models.
ii. Loss in Data Diversity and Versatility:
Modern data analytics, ML, and AI models require high levels of detail and quality. Data anonymization strips away much of the core features of the dataset making it impossible for the model to learn any advanced concepts.
iii. High Data Drifts:
AI/ML models require dynamic data to improve and match ever-changing real-world trends continuously. Using anonymized data created a time-consuming and costly cycle to continuously update training datasets with new data which is anonymized first and then updated.
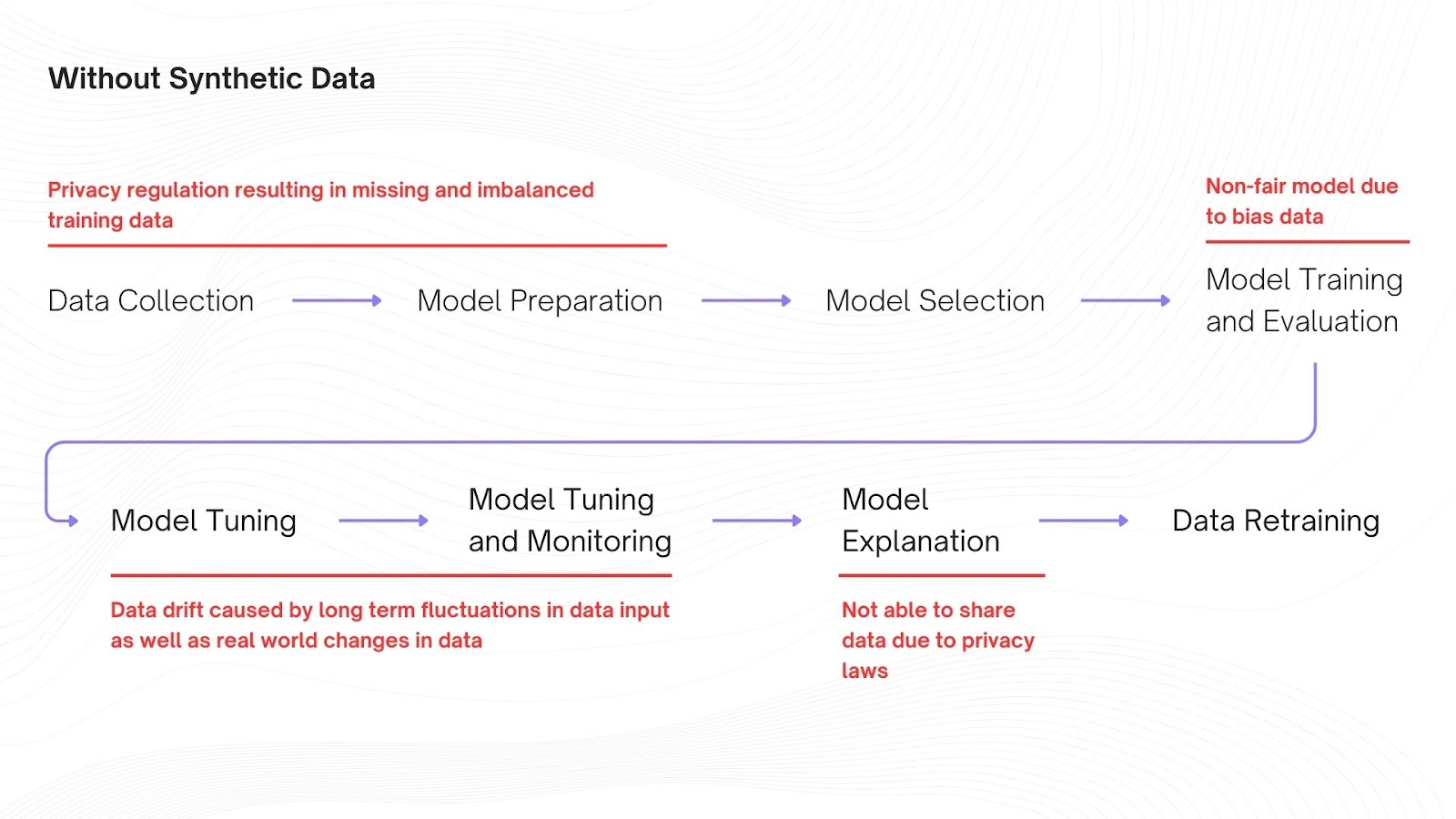
Learn more about the inverse relationship between data anonymization and machine learning, here.
b. Machine Learning using Tabular Synthetic Data:
i. High-Quality Synthetic Data:
Since synthetic data mimics real data without any encryption or masking it is a rich resource for training AI/ML models. Synthetic data can also be trained to remove biases and balance real data, fill in missing values, and create more data for rare scenarios making it the most sustainable and productive source for data analytics, training machine learning models, and developing artificial intelligence.
ii. Scalability and Versatility:
Since synthetic data can be enhanced using limited datasets. Organizations can use synthetic data which can be generated in unlimited quantities to match their large language models which require large and in-depth training datasets. And since synthetic data is programmatic we can update these datasets to fill in new and upcoming trends mirroring real-world data decreasing the chances of data drifts.
iii. Data Security:
Since synthetic data is fake data that does not contain any PII there is no risk of reidentification making it easier and faster to share synthetic training data and models trained on it with internal and external stakeholders for validation and input without waiting in line for approvals from the data privacy teams.
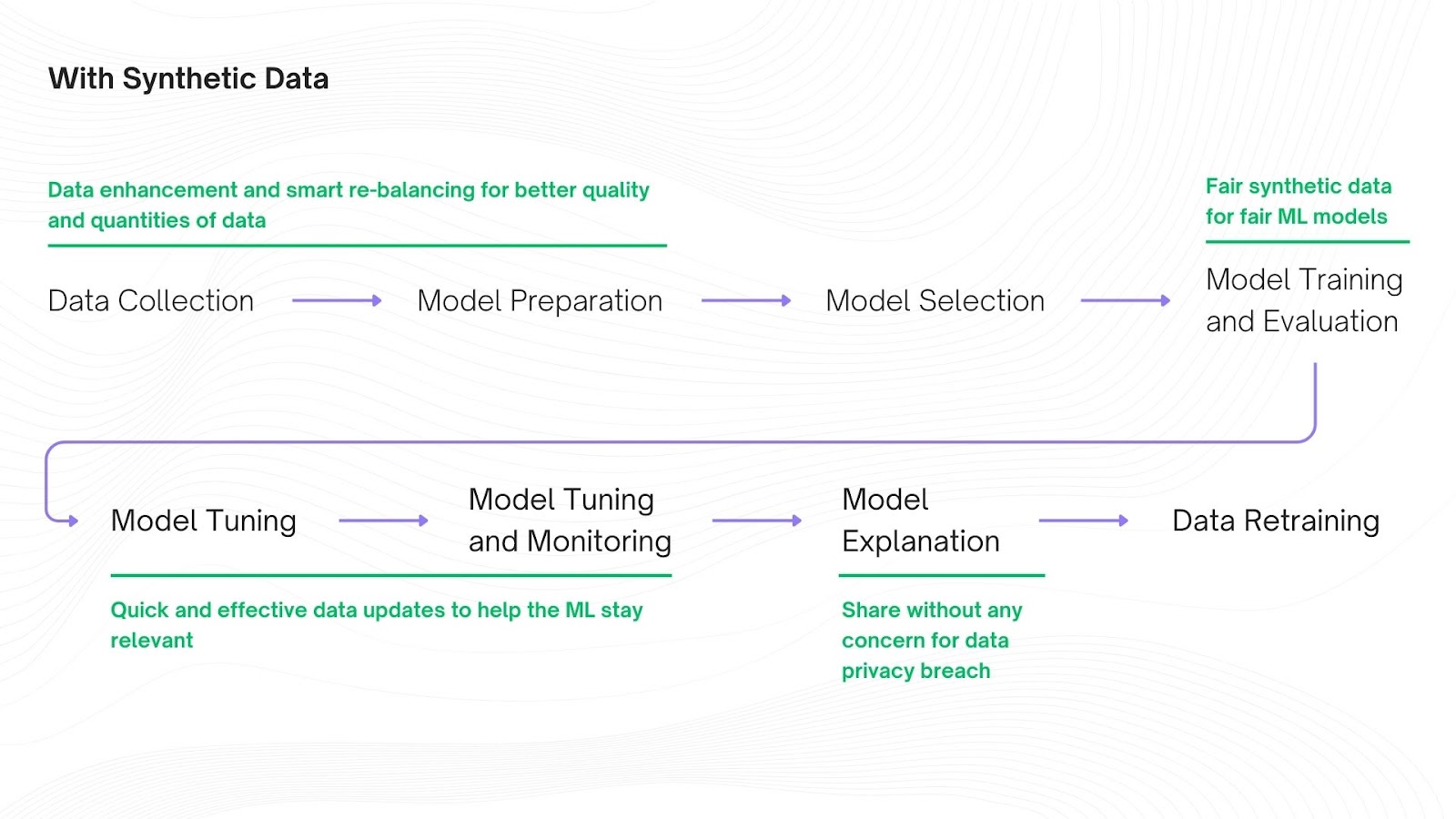
Learn more about the benefits of using synthetic data for training ML/AL models, here.
4. Synthetic Data Generation Methods
a. Generative Adversarial Networks (GANs):
A Generative Adversarial Network (GAN) is an unsupervised method to generate tabular synthetic data. A GAN has two sub-models or neural networks called a generator and a discriminator which essentially compete against each other to create an output that cannot be differentiated from reality. Hence the name ‘adversarial.’
Discriminator: In every GAN model a discriminator is trained first to recognize real data as it is. The generator is activated once the discriminator learns to tell what is real data and what is fake data.
Generator: A generator (as the name suggests) generates fake or synthetic data and sends it to the discriminator for analysis. The generator then receives feedback from the discriminator on whether this is real or fake data. The generator re-trains itself to generate better quality fake data until the discriminator cannot differentiate between real data and synthetic data.
The GAN continuously runs the same program in cycles where the generator tries to fool the discriminator and the discriminator tries to prove this is fake data. This cycle creates a model that produces high-quality synthetic tabular data good enough to fool the discriminator hence good enough to fool humans.

b. Large Language Models (LLMs):
Another method to generate tabular synthetic data is through LLMs which simply put is done by feeding a real dataset in a pre-trained transformer-based model such as GPT-4, BERT, Llama, etc, and adding a set of seed queries that tell the LLM what output to generate.
For generating synthetic data two types of LLMs are generally used,
i. Self Improvement:
These models are self-evaluating and self-training, used in instances where the models need to adapt to different data elements over time or are set in volatile environments where data is continuously changing. Different from GANs which use feedback from a discriminator to evolve, self-improvement models asses themselves based on set parameters and expected outputs using feedback loops, exploration, exploitation, reinforced learning, and so on to continuously improve the quality of synthetic data outputs
ii. Distillation:
These models are trained to mimic the behavior of larger more complicated models making it easier to generate synthetic data faster and with lesser computational power but with the same results as a large sale LLM would give. This process is often dubbed as a ‘teacher-student’ relationship where the teacher is the large-scale LLM who distills or transfers information to the smaller hence efficient LLM referred to as the student. Some common distillation techniques are,
- Self Instruct: Self Instruct is when a model teaches itself by generating its own data and tasks to learn from. It’s like setting up your own study plan and creating your own quizzes to test yourself.
- Evol Instruct: Evol Instruct involves gradually increasing the difficulty of tasks given to the student model. It's like starting with simple math problems and moving on to complex ones as you improve.
- LAB (Learning Augmented by Baseline): LAB involves comparing the student's performance against a baseline or reference model to help it learn better. Imagine you’re practicing shooting a ball and have a coach (the baseline) showing you how to improve each shot.
- Task Specific: Task Specific distillation focuses on teaching the student model-specific tasks. For example, instead of learning everything about language, it might only learn how to answer questions or summarize texts.
- Knowledge Specific: Knowledge-specific distillation targets specific areas of knowledge to pass on from the teacher to the student. It’s like learning just the chemistry section from a science book, rather than everything in it.
The process to generate tabular synthetic data using LLMs, looks something like this,
i. Data Preparation:
Original data is collected, cleaned, and formatted broken down into chunks along with identifying and selecting features or attributes that will serve as the reference point for the LLM to generate synthetic data.
ii. Model Selection and Fine-Tuning:
A pre-trained LLM that has been trained on large-scale data is selected. The LLM can be also fine-tuned by training it on the original dataset using supervised learning etc. to adapt it to the domain-specific features or attributes.
iii. Prompt Engineering and Seed Queries:
A prompt is an instruction for the LLM on how to generate synthetic data while a seed query is a specialized prompt that gives the LLM a starting point to generate a variety of datasets. While both are closely related they differ in the fact that the prompt guides the output of the LLM and controls the response while the seed query controls the input and is used for data exploration to generate a diverse set of results based on the set parameters.
The synthetic data is then generated using the designed prompts on the pre-trained and fine-tuned LLM. Based on the expected output we can control the parameters through temperature and tokens and post-process the generated synthetic data through data validation, quality assurance metrics, synthetic data privacy scores, and so on until we reach the desired output.
.png)
But why should enterprises go through all this trouble of setting up a new system for generating tabular synthetic data in the first place? For one, Enterprises themselves do not have to set up these systems. Synthetic data generation companies like ourselves i.e. Betterdata have already created the system, models, and process to generate high-quality and privacy-preserving synthetic data using advanced algorithms to train GANs and LLMs to generate highly realistic fake data in minutes improving your data downtime, ability to share and use, and protect data privacy. Secondly, big data data analytics, AI/ML modeling, and so on are no longer possible through anonymized data due to strict data privacy laws. This limits innovation and prolongs the time required to complete time-sensitive and crucial tasks to months. Using synthetic data the same tasks can be completed in days without exposing private data.
